 Новости RSS
Новости RSS
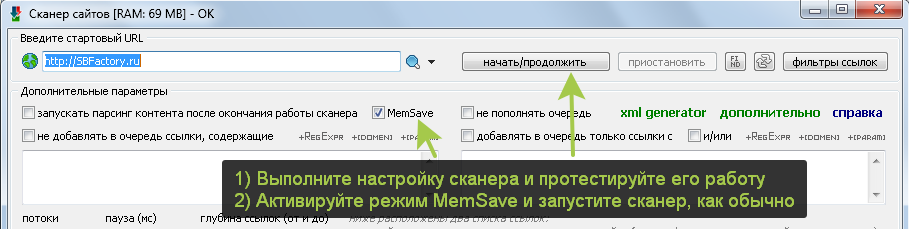
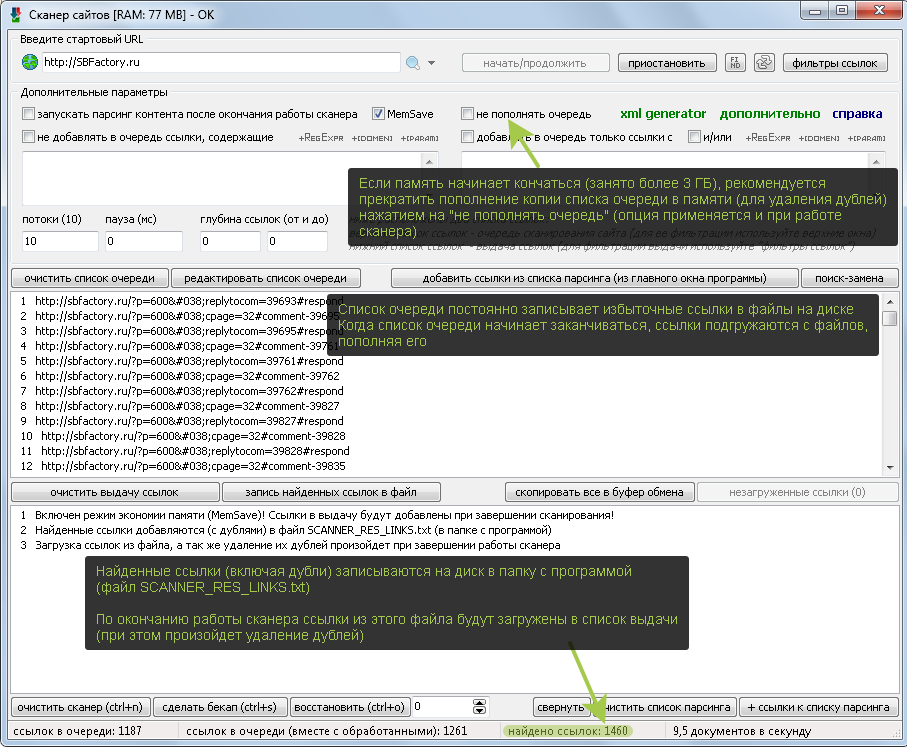
В обновлении 11.1.0000555 (05.12.2018) введена подсветка базовых макросов шаблона вывода. Это позволяет более эффективно ориентироваться в коде.

Теперь можно легко увидеть операторы разделителей CSV, макросы границ парсинга, комментарии к коду, вложенные блоки кода и другое.
Если потребуется, со временем введем подсветку и других макросов.
(more…)
 Рубрики:
Рубрики: 
 Теги:
Теги: 

 С вопросами о покупке (или другими организационными), вы можете в любое время обращаться по Телефону +7 983 381 3211 или Телеграм @ContentDownloaderX1 (Сергей Владимирович)
С вопросами о покупке (или другими организационными), вы можете в любое время обращаться по Телефону +7 983 381 3211 или Телеграм @ContentDownloaderX1 (Сергей Владимирович)
 WBApp (дополнение для Content Downloader) - парсинг с выполнением WEB-скриптов, с возможностью имитации кликов по элементам страниц, произведение прокрутки страниц, заполнение текстовых полей и многое другое...
WBApp (дополнение для Content Downloader) - парсинг с выполнением WEB-скриптов, с возможностью имитации кликов по элементам страниц, произведение прокрутки страниц, заполнение текстовых полей и многое другое...