 При желании в менеджере заказов вы можете приобрести услуги по настройке или персональному обучению
При желании в менеджере заказов вы можете приобрести услуги по настройке или персональному обучениюНавигация:
![]() Как сканером сайтов выполнять поиск ссылок только в определенных частях WEB-страниц сайта
Как сканером сайтов выполнять поиск ссылок только в определенных частях WEB-страниц сайта
![]() Использование режима экономии памяти (для парсинга огромных сайтов с целью поиска огромного количества ссылок, гораздо больше миллиона)
Использование режима экономии памяти (для парсинга огромных сайтов с целью поиска огромного количества ссылок, гораздо больше миллиона)
Для возврата к меню навигации используйте клавишу home
Предназначение
 Сканер сайтов предназначен для сбора определенных ссылок со всего сайта или с какой-то его части. Программа “ходит” по всем найденным страницам и собирает ссылки, удовлетворяющие заданным фильтрам.
Сканер сайтов предназначен для сбора определенных ссылок со всего сайта или с какой-то его части. Программа “ходит” по всем найденным страницам и собирает ссылки, удовлетворяющие заданным фильтрам.
Видео об основах
Как вызывается
Сканер сайтов вызывается нажатием кнопки “сканер сайтов (сбор ссылок с сайта)” на панели инструментов главного окна программы (ctrl+7).
Принцип работы
 |
 Сканер берет первую ссылку из окна “список очереди” И УДАЛЯЕТ ЕЕ ИЗ СПИСКА, загружает по ней web-документ и ищет в нем все url-адреса (ссылки). Ссылки, которые “пройдут” через фильтры очереди попадают в список очереди. Ссылки, которые “пройдут” через фильтры ссылок (читать про фильтры ссылок), попадают в список найденных ссылок. Примечание: имеющиеся фильтры очереди работают по такому же принципу, как и фильтры ссылок! Во время работы сканера, cписок очереди постоянно пополняется новыми найденными ссылками, содержащими в себе урл сайта (в данном случае sbfactory.ru, ссылки на другие сайты не попадут в список очереди). В список очереди могут добавляться ссылки с доменными именами третьего уровня (например, http://forum.sbfactory.ru). В список очереди и в список ссылок не могут попасть дубли url-адресов! Сканер сайтов будет продолжать работу, до тех пор, пока не “закончатся” все ссылки в списке очереди. |
Как использовать
Для запуска сканера необходимо ввести стартовый url или добавить ссылки в список очереди. После этого нужно нажать кнопку “начать/продолжить сканирование”.
Процесс работы сканера можно как приостановить, так и продолжить в любой момент времени (используйте соответствующие кнопки).
ВНИМАНИЕ!!!: Список очереди (также его дубликат в памяти) и список найденных ссылок очищаются только при перезапуске программы или при нажатии кнопок “очистить список очереди”, “очистить список найденных ссылок” (соответственно).
Важно понять и то, что дубликат списка очереди (который содержится в памяти программы) не “теряет” элементы в процессе работы сканера, а постоянно пополняется. Это исключает возможность появления в нем одинаковых ссылок, что в свою очередь позволяет не обрабатывать дважды одну и ту же ссылку.
Очистить список очереди и его невидимый дубликат (в памяти) можно нажатием на кнопку “очистить список очереди”.
Если на сайте необходима авторизация, то используйте кнопку “авторизация/cookies” или кнопку “дополнительно” во вкладке “контент”.
Что делать, если сканер на каком-то сайте не находит все желаемые ссылки или не находит ссылки вообще! – КОНЕЧНО ЖЕ, АНАЛИЗИРОВАТЬ ПОЛУЧАЕМЫЙ ИМ ОТ САЙТА КОД!!!
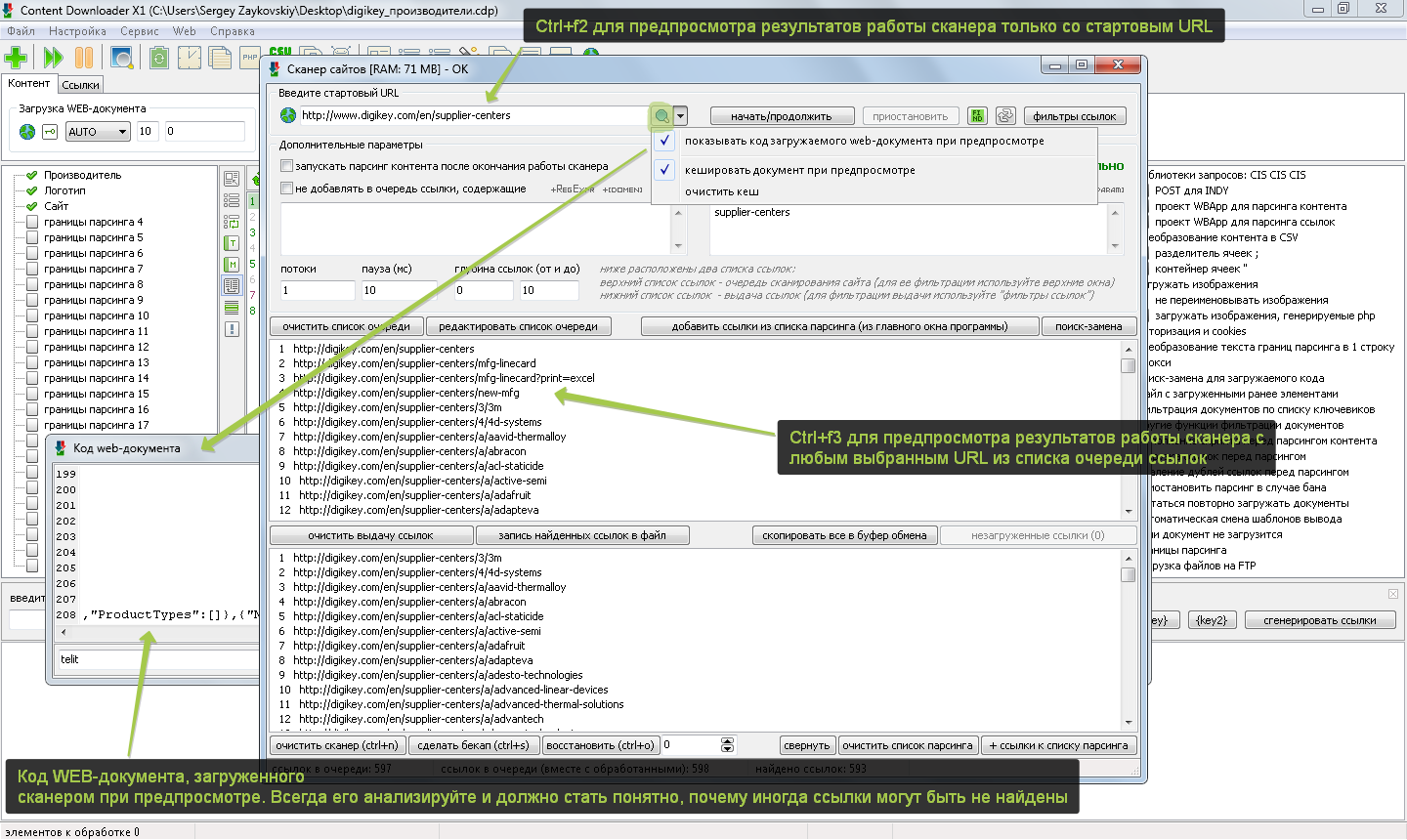
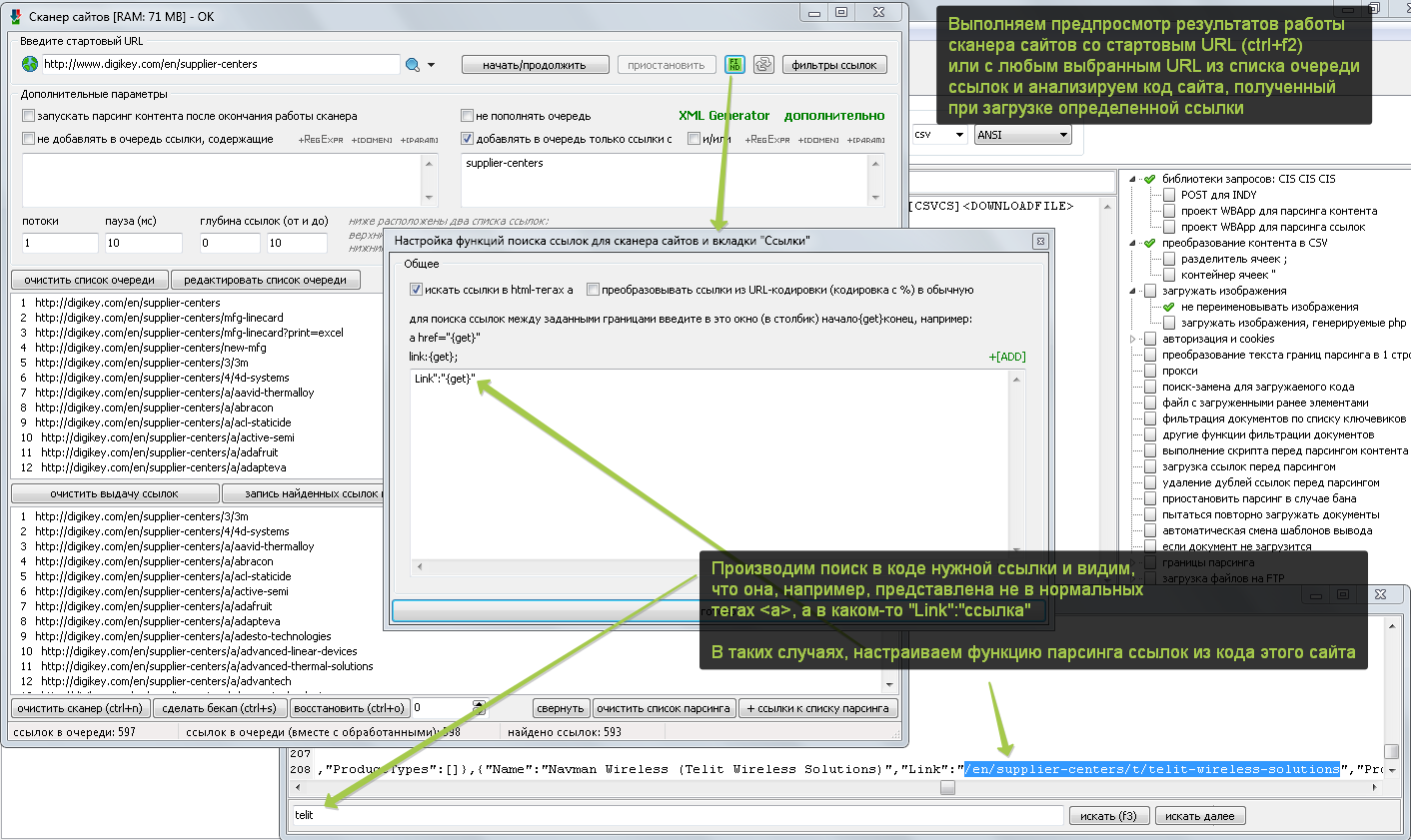
Примечание: Некоторые сайты вообще могут не отдавать код или отдавать код не полностью для стандартной библиотеки HTTP-запросов программы (часть контента генерируется/подгружается скриптами WEB-документа в процессе его выполнения). Выбрать/настроить библиотеку HTTP-запросов можно в окне настроек HTTP-запросов программы (ctrl+h).
Если есть проблемы с загрузкой WEB-страниц, выберите библиотеку WIN.
Если какой-то нужный контент не присутствует в коде загружаемого WEB-документа, скорее всего он подгружается/генерируется скриптами. Чтобы парсить с обработкой скриптов, выберите библиотеку Internet Explorer (DOM).
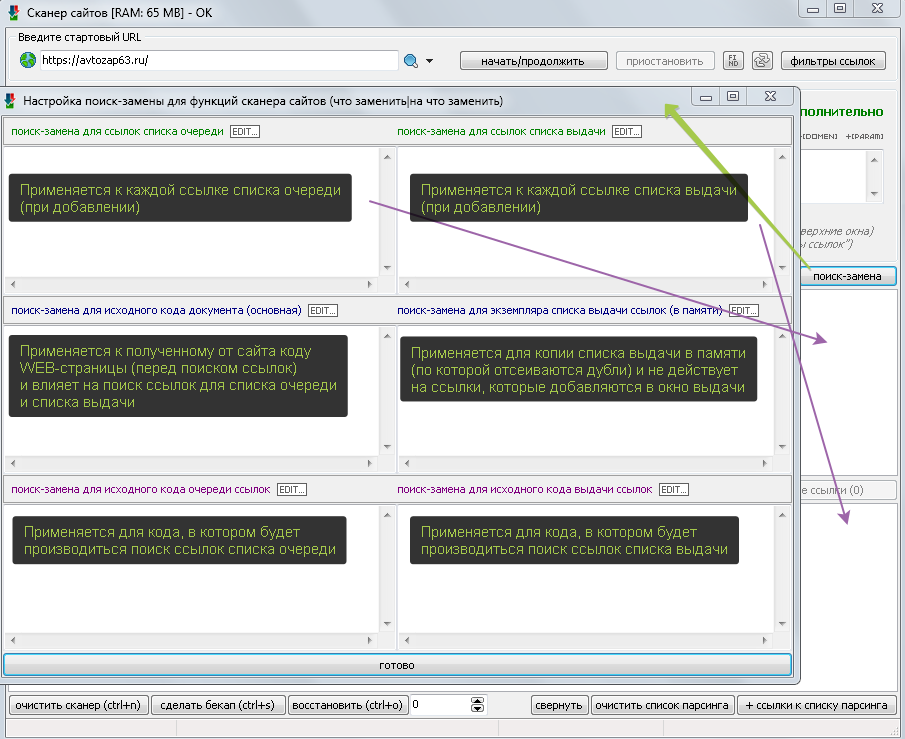
Описание функций поиск-замен для основного загружаемого кода, кода для списка очереди и кода для списка выдачи ссылок
Как сканером сайтов выполнять поиск ссылок только в определенных частях WEB-страниц сайта
Использование режима экономии памяти (для парсинга огромных сайтов с целью поиска огромного количества ссылок, гораздо больше миллиона)
Программе выделяется около 3,5 ГБ памяти (вне зависимости от количества оперативной памяти компьютера). Количество использования процессом памяти можно смотреть в диспетчере задач системы (ctrl+alt+delete). Если программа будет занимать более 3,5 ГБ памяти, возникнут ошибки.
Для парсинга огромных сайтов и для поиска огромного количества ссылок (гораздо больше, чем миллион) рекомендуется использовать режим работы сканера MemSave
Примечание: При парсинге с активированным режимом MemSave нельзя использовать создание и восстановление бекапа (ctrl+s/ctrl+o). Также не следует приостанавливать и возобновлять работу сканера. Настроили сканер, проверили, как он работает, активировали режим MemSave и запустили его, пусть сканирует до завершения без остановки.
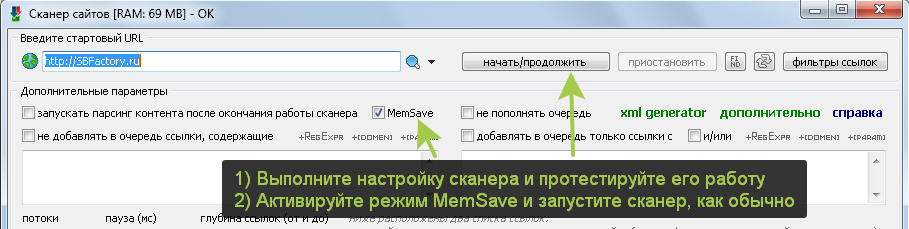
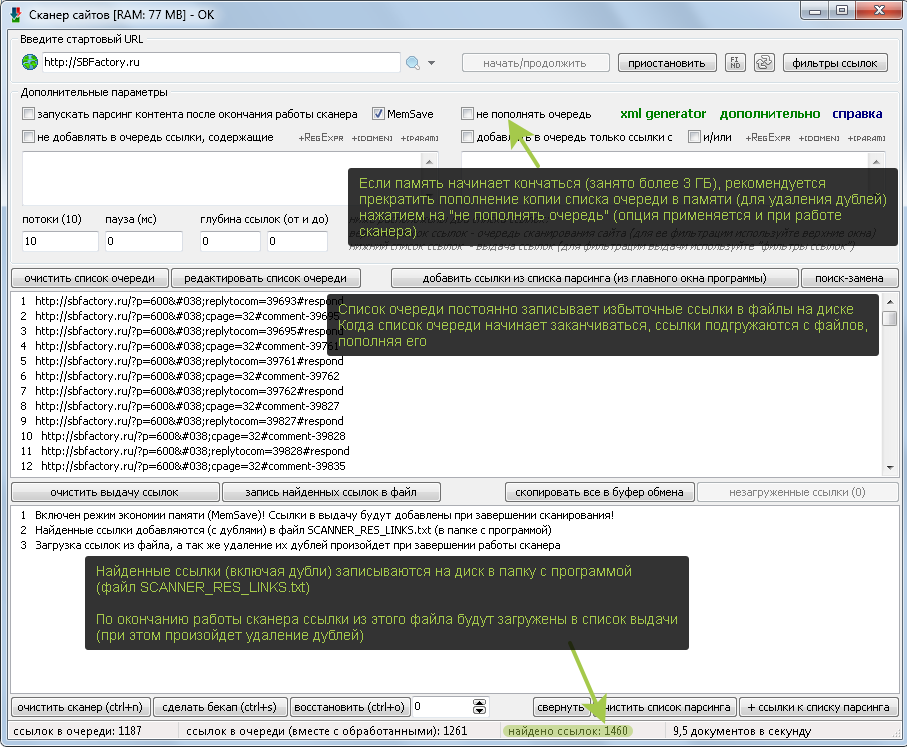
Важно понимать: Чтобы максимально эффективно расходовать память в режиме MemSave нужно настроить фильтры очереди таким образом, чтобы сканер проходил только по нужным ссылкам (не уходя на лишние). Так как основную память в этом режиме занимает только копия списка обойденных ссылок (который обязателен и нужен для предотвращения повторного обхода ссылок)!
 (оценок: 18, средний балл: 5.00)
(оценок: 18, средний балл: 5.00)![]() Loading...
Loading...
А как быстро например распарсится сайт на 60 тысяч страниц?
Отпишите в мыло плиз.
Примерно по 10 страниц в секунду (100 минут) (зависит от скорости самого сайта).
лагает парсер, из 88-и собрал тока 24. Сайт на вп, если интересно – адрес мылом дам
Смотрите меню-сервис-смотреть лог…
Дабы не навести тень на саму прогу – прога супер! Просто сайт попался “с закаулками” 🙂
А прогу без сомнения двинул бы на Национальный Продукт!
Реально доступная логика и восхищающие производительность и функционал.
Более того – и автор действительно серьезный мужик: и ФАК достойный уважения, и сайт продукта, и обновления, и действительно доступная стоимость для Рунета – вот есть у нас настоящие кодеры!
Работает ли опция не по стартовой ссылке а по рабочему проекту?
Т.е. если отработал проект но нужно проверить “донора” на предмет новых страниц, с их “импортом” на основании условий проекта, но с обязательным перечнем новых страниц. Как это сделать?
Нужно подключить “файл с загруженными элементами” во вкладке “контент”.
Тогда при следующем парсинге загруженные ранее ссылки не будут обрабатываться.
При сборе ссылок для парсинга столкнулся с такой проблемой: если на сайте доноре ссылки содержат в себе пробел, CD при сборе этих ссылок убирает пробелы и получается уже другой url который ведет на страницу ошибок… Как с этим бороться?
Прошу дать мне ссылку на такую страницу (где есть линки с пробелами).
Залил обновленный файл (без выпуска официального обновления).
Скачайте программу отсюда http://sbfactory.ru/cdfiles (доступ вы получили при покупке ключа)
В меню – справка – о программе должно быть “27.77 MK III”
В этой версии ошибка с пробелами в ссылках исправлена, проверяйте!
Благодарю за оперативность. Приятно удивлен таким отношением.
Пожалуйста. Рад помочь!
Обращайтесь!
Ребята, час ночи и не могу понять ))
под проксёй eng нужно отсканировать выдачу гугла также под проксёй в самой проге. Дело в том, что гугл что-то изменил в своих чпу и ссылки совсем непонятные. Убрав все параметры фильтров, прога всё равно виснет и не движется. Подскажите решение!
Может прокси “дохлые” или не работают в программе?
да, на самом деле из-за прокси, ложная тревога ) ещё раз спасибо за софт!
Добрый день.
Нужно запарсить сайт со следующей структурой:
http://www.domen.ru/shop/98765/87654.html
то-есть, после shop идет ровно две вложенности с кодами. В данном случае 98765 и 87654. Первый код: категория, второй: код товара.
Также на сайте попадаются и другие ссылки на товары. Эти ссылки могут быть вида: http://www.domen.ru/shop/98765/98744/87654.html
где 98744 – например какая-то характеристика данного товара. Например, диагональ 7 дюймов.
Нужно парсеру указать, чтобы он брал только ссылки с двумя вложеностями.
Маску, что-ли.
Типа: http://www.domen.ru/shop/*/*.html
Есть такая возможность?
В справке не нашел.
Спасибо.
Здравствуйте.
Выставить глубину ссылок 4-4.
В ходе сканировании сайта большое число ссылок залетает в “не удалось загрузить”. Об этом свидетельствует счетчик таких ссылок. Что это такое, ссылки, которые “не удалось загрузить”? Можно ли объяснить причину того, почему они оказываются незагруженными?
Либо сайт не ответил на запрос программы, либо в коде попалась битая ссылка (404), либо ошибка 403 и прочие…
как вытащить все папки из сайта в котором они скрыты
нужно получить все файлы пдф из всех папок http://www.mab.lt/paveldas/*/*/*.pdf
http://www.mab.lt/paveldas/MAB01/230001/232328-1906-1.pdf
Используя регулярные выражения в фильтрах ссылок.
Задать шаблон для ссылок:
re:регулярное выражение
У меня тоже вопрос по ссылкам которые “не удалось загрузить”, раньше все ссылки собирались нормально, а теперь почему то большая их часть не загружается. В чем может быть проблема?
Может быть вас сайт забанил.
Переподключите интернет (чтобы сайт вас разбанил) и пробуйте парсить в 1 поток.
Если название домена русскими буквами, то не сканирует ничего!. Может есть какое решение?
Доработали.
Спасибо!
А можно ли с помощью сканера сайтов, получить ссылки только с текущей (стартовой страницы), чтоб сканер не лез вглубь других страниц?
Да.
Включите ЧекБокс “не пополнять очередь”.
Можно. Пользуемся вкладкой ссылки.
Возможно как то создать список всех внешних ссылок на сайте ?
Да, используйте соответствующий фильтр в фильтрах ссылок.
Если бы он еще искал и внешние ссылки на сайте, то цены бы ему не было.
Теперь ищет. Смотрите соответствующий фильтр в фильтрах ссылок.
Если в сканер задать ссылку на файл (C:\content\1.htm), он пытается загрузить адрес http://C:/content/1.htm и файл не загружается. Можете исправить?
Здравствуйте.
Тут нечего исправлять.
Сканер сайтов не предназначен для работы с локальным диском. С локального диска можно парсить во вкладке “ссылки” или “контент”.
На некоторых сайтах почему-то сканер сайтов очень выборочно выдирает страницы типа page=№, многие страницы оказываются пропущены. Причём это не зависит от числа потоков, я выставлял 1 поток. Чаще всего почему-то спарсивается page=4, при этом page=2, 3, 5 и т.д. оказываются пропущены.
Если хотите, могу прислать проект парсинга (куда?)
Здравствуйте.
Скорее всего это особенность сайта, или так настроен сканер. Если вы думаете, что это ошибка, пожалуйста, вышлите мне на почту sbfroot@gmail.com КОНКРЕТНЫЙ адрес WEB-страницы на которой сканер не находит той или иной ссылки (с указанием этой ссылки, которую(ые) не находит). Изучением “подозрительных проектов” мы не занимаемся, уж простите =)
С уважением к вам, Сергей.
простой вопрос к примеру
на форуме есть информация с текстом об
нужной мне допустим инструкции или упоминается тема нужная мне
в названии программы если быть точным в тексте
а еще у меня допустим 10 форумов по программированию и там допустим по ключевому слову появляется новая информация и я бы сканировал сайт а лучше 10 по очереди сайтов
по списку ключевых слов и к вечеру примерно сел бы почитал бы что и кто на эту тему пишет и какие у него алгоритмы и размышления ( всё для обучения быть умнее и не тратить время на тупые кликания по кривым поискам на сайтах в форумах и дебрях )
ваша программа может это ?
и мне нужен готовый список ссылок где это (список слов ключевых или или типа ) встречается
а еще вопрос по тайм ауту и планировщику задачи раз в 3 дня к примеру про сканировать или раз в 1 день
Здравствуйте.
Пожалуйста, задавайте вопросы на форуме http://forum.sbfactory.ru/
Спасибо!
Доброго времени суток!
Не получается парсить ссылки с avito и с reformagkh.ru. Сканер сайтов запускается и практически сразу останавливается с пустым списком. Связано ли это только с отсутствием у меня IE 11? Или же проблемы с авторизацией? Где посмотреть полноценную инструкцию с описанием как авторизовываться с помощью cookies post или с помощью proxy? заранее благодарю за ответ
С сайта реформажкх парситься нормально, и с авито также. IE11 лучше поставить. и последнюю версию CD. Попробуете открыть в самом IE страницу сайта, и если не открывает то тогда настройках самого браузера в ствойствах параметры безопастности. А по программе проблема решается так
Нажмите ctrl+h, включите там Internet Explorer (DOM), ниже “тайм-аут проверки…” измените на 2222
Пробуйте парсить в 1 поток!!!
И еще
Возможные решения:
1) Вставить нужные для парсинга этого сайта cookies и/или HTTP-заголовки в ctrl+h;
2) Использовать библиотеку Internet Explorer (DOM) в ctrl+h (но парсить с ней можно максимум в 1-2 потока).
Вопрос 2. Что делать если при задании границ парсинга вышла ошибка “Программе не удалось загрузить WEB-страницу (Socket Error # 0 )”?
Здравствуйте.
Пожалуйста, задавайте вопросы на форуме.
Спасибо!