 Новости RSS
Новости RSS
Здравствуйте!
WEB-страница доступна только для чтения! Если у вас есть какие-либо вопросы, можете задавать их на форуме http://forum.sbfactory.ru/
Спасибо!
ЕСЛИ У ВАС ПРОБЛЕМА С ОТОБРАЖЕНИЕМ ТЕКСТА ИНТЕРФЕЙСА ПРИ УСТАНОВКЕ ПРОГРАММЫ, ОБРАТИТЕ ВНИМАНИЕ НА ЭТОТ ВАРИАНТ ЕЕ РЕШЕНИЯ!
Рекомендации по заданию вопросов:
1) Постарайтесь максимально подробно изложить все детали вопроса (чтобы мы ясно понимали, что вы делаете/что требуется получить/какие именно функции используете и так далее…) и, вероятно, мы вам сразу дадим ответ без дальнейшей переписки с целью выяснения нюансов;
2) Для публикации макросов или HTML-кода используйте кнопку “code” над формой ввода текста комментария.
Учтите! В разделе FAQ задаются вопросы следующего вида:
– Есть ли в программе такая-то функция?
– Как можно реализовать подобный алгоритм действий?
– Почему при парсинге происходит то-то или то-то?
– …
Иными словами: Раздел FAQ предназначен для осуществления консультаций.
Другие вопросы, которые требуют от нас изучения/доработки ваших файлов проектов, изучения сайтов, продумывания новых или специфичных алгоритмов для парсинга определенных данных с указанных ресурсов (т.е. где требуется выполнить работу) решаются платно! Их решают специалисты по настройке в индивидуальном порядке! Как заказать услуги специалистов по настройке (клик).
Примечания:
1) Мы в праве отказать в предоставлении ответов на некоторые вопросы без пояснения причин!
2) Мы в праве удалять любые комментарии без пояснения причин!
С уважением к вам, администрация сайта.

 (оценок: 7, средний балл: 4.43)
(оценок: 7, средний балл: 4.43) Рубрики:
Рубрики:  Теги:
Теги:  С вопросами о покупке (или другими организационными), вы можете в любое время обращаться по Телефону +7 983 381 3211 или Телеграм @ContentDownloaderX1 (Сергей Владимирович)
С вопросами о покупке (или другими организационными), вы можете в любое время обращаться по Телефону +7 983 381 3211 или Телеграм @ContentDownloaderX1 (Сергей Владимирович)
 WBApp (дополнение для Content Downloader) - парсинг с выполнением WEB-скриптов, с возможностью имитации кликов по элементам страниц, произведение прокрутки страниц, заполнение текстовых полей и многое другое...
WBApp (дополнение для Content Downloader) - парсинг с выполнением WEB-скриптов, с возможностью имитации кликов по элементам страниц, произведение прокрутки страниц, заполнение текстовых полей и многое другое...
Взято от комментария Владимира (http://sbfactory.ru/?p=1301&cpage=36#comment-35449)
Добрый день! При импорте файлов в WordPress столкнулся с проблемой невозможности импортировать миниатюры (Features image). В интернете много про это написано, но решения, подходящего для нашего инструмента так и не нашел. В итоге на основах разных решений слепил свое (может не самое профессиональное, но работающее), и хотел бы им поделиться дабы люди не тратили пару дней, как я :-). Если посчитаете это полезным, можно было бы вынести его в общее пользование:
1) Для начала при парсинге задаем метаполе с путем к фото на сервере назначения: [POSTMETA]attached_f////wp-content/uploads/2016/09/[/POSTMETA] ,где получается вида “featuresimage.jpg”.
2) Скачанное фото и заливаем по ftp на сервер назначения именно по этому пути: www site ru/wp-content/uploads/2016/09/featuresimage.jpg
3) В файл function.php вашей темы в самый низ добавляем код:
function auto_featured_s_image($post) {
global $post;
if( has_post_thumbnail($post->ID) )
return;
$filename = get_post_meta( $post->ID, 'attached_f', true );
if (empty($filename) ){
return;
}
$filetype = wp_check_filetype( basename( $filename ), null );
$wp_upload_dir = wp_upload_dir();
$attachment = array(
'guid' => $wp_upload_dir['url'] . '/' . basename( $filename ),
'post_mime_type' => $filetype['type'],
'post_title' => preg_replace( '/\.[^.]+$/', '', basename( $filename ) ),
'post_content' => '',
'post_status' => 'inherit'
);
$attach_id = wp_insert_attachment( $attachment, $filename, $post->ID );
set_post_thumbnail($post->ID, $attach_id);
require ABSPATH . 'wp-admin/includes/image.php';
// Создадим метаданные для вложения и обновим запись в базе данных.
$filen = $wp_upload_dir['path'] . '/' . basename( $filename );
$attach_data = wp_generate_attachment_metadata( $attach_id, $filen );
wp_update_attachment_metadata( $attach_id, $attach_data );
update_post_meta($post->ID, 'svtle-main-content', $filen);
}
// Use it temporary to generate all featured images
add_action('the_post', 'auto_featured_image');
// Used for new posts
add_action('save_post', 'auto_featured_s_image');
add_action('draft_to_publish', 'auto_featured_s_image');
add_action('new_to_publish', 'auto_featured_s_image');
add_action('pending_to_publish', 'auto_featured_s_image');
add_action('future_to_publish', 'auto_featured_s_image');
4) Создаем файл импорта при помощи “Обработка и импорт в КМС”, и импортируем стандартным плагином WordPress.
5) После обновления всех миниатюр удаляем код из functions.php, чтобы не грузился хостинг.
Все, картинки для миниатюры добавляются из метаполя, далее прикрепляются к посту, и им присваивается id, по которому они назначаются миниатюрой, и обновляются их метаданные.
Если постов большое количество (у меня было около миллиона), то сразу все миниатюры не установятся. В таком случае можно было придумать много способов для обновления всех постов, но я запустил webapp на админку сайта, чтобы он перебирал страницы с постами (вывод по 10 штук). За ночь все посты обновились.
Не могу справится со сканированием сайта. Сканер получает только ссылки с первой страницы. Остальная инфа грузится с того же url динамически – её получить не удаётся.
Можно ли такое вообще провернуть сканером?
Вот адрес страницы:
vamsvet ru/catalog/section/newgoods
А это ссылки, по которым догружается контент:
vamsvet ru/catalog/section/newgoods/#p2
vamsvet ru/catalog/section/newgoods/#p3
Здравствуйте.
Загрузка данных на этом сайте осуществляется WEB-браузером при выполнении WEB-страницы с адресов типа http www vamsvet ru/catalog/section/newgoods/?catalog_ajax_call=Y&PAGEN_1=7&items_only=N
Можете сгенерировать список таких страниц http://sbfactory.ru/cd/?p=999 и парсить с них нужные вам данные.
С уважением к вам, Сергей.
Спасибо огромное. Удалось.
Здравствуйте. Ребята огромная просьба подсказать по дополнительным границам парсинга.
Вопрос? Если при задании границ парсинга присутствует например слово КОМПЬЮТЕР, то такой документ вообще игнорировать и при парсинге эту ссылку не учитывать, то есть вообще игнорировать и не парсить?
Заранее огромное спасибо за ответ.
Приветствую, актуально ли сейчас парсить яндекс маркет программой? Или не работает? Где можно актуальную инструкцию глянуть?
Добрый день.
[DFN][/DFN]
[DOCNAME].htm[/DOCNAME]
При таком виде шаблона вывода программа в файл htm добавляет в начало имя загружаемого файла (). Как исправить шаблон, чтобы имя файла не добавлялось?
подскажите где почитать и есть ли возможность генерировать ссылки для парсинга с параметрами key и num? но при этом брать эти параметры из файла или таблицы в эксель (например для такого-то key такое-то значение и num), чтобы каждые раз не нажимать сгенерировать ссылки и не вводить эти параметры вручную, для большого количества ссылок
пока пониаю, что можно задать только 1 параметр num, и к по нему сгенерировать ссылки для всех значение параметра key, но в моем примере параметр num разный для различных kеу
еще не появилаось ли возможность задать границу парсинга текстом не из кода страницы, а произвольно, фиксированым текстом? очень бы облегчило назначение имен и задание сохранения путей файлов, а то так при парсинге каждой картинки приходится менять название папки подкаталога
спасибо
Здравствуйте.
Такой возможности нет.
С уважением к вам, Сергей.
Добрый день! По моему не работает оператор prevskip в функциях замены, в итоге воспроизвел примеры из подсказок – не функционирует…
a{skip}c|d
{prevskip}|_
И есть ли решение с помощью макросов замены убрать (заменить) путь к фото в коде, Например:
<td width="117">
<img src="http://donor.ru/images/dji-authorized-dealer2.jpg">
</td>
на
<td width="117">
<img src="dji-authorized-dealer2.jpg">
</td>
Спасибо!
Добрый день! Суть проблемы в том что страница долго загружается, поэтому
при задании границ парсинга в просмотре кода не загружаются фотки (они подгружаются Аяксом долго), а ниже в браузере уже подгрузились.
Поэтому сложно выбрать границы.
Что делать в такой ситуации. Сайт 1688.com.
Доброго времени дня Вам!
Возможно ли использовать ВАшу программу для парсинга картинок через гугл яндекс и тд. с возможностями фильтрации источников контента (wiki, VK. и т.д.), имеется ввиду насколько это юзабельно (настройка прокси, названий файлов, количества скачиваемых картинок или страниц по запросу, размеры картинок, типы фото, лица и тд. и т.п.)
Надеюсь на ваш ответ =/
парсится часть кода, в котором есть картинки, можно ли чтобы эти картинки грузились не в одну папку, так как у картинок разные пути, но одинаковы названия
напр.
site.ru/papka1/image.jpg
site.ru/papka2/image.jpg
и в итоге вторая картинка заменит первую.
можно конечно изменить название картинок, но тогда одни и те же картинки будут много дублей
Доброй ночи!
Сергей, скажите, пожалуйста:
Как то можно использовать разные прокси, для getmorecontent c WBAMODE, Когда getmorecontent находится внутри повторяющейся границы?
А то у меня CD заходит 20 раз подряд с одного и того же прокси по getmorecontent и яндексу это не нравиться, и он меня обрубает.
Спасибо.
Сергей, еще хотел спросить:
А функция, заменять мнемоники на их символы, поменяла алгоритм работы?
Раньше по моему было, если ее включишь, то она заменяла мнемоники всегда до, того как программа показывает код.
А сейчас включишь ее, а в меню задания границ парсинга, мнемоники показываются. А перейдешь потом в шаблон отображения, а он не показывает границу, потому что мнемоники заменены уже в коде, а в границе парсинга они назначены. Это при парсинге яндекса у меня так, или это у меня проблемы ?
Я понял, это происходит при использовании библиотеки clever internet Suite, видимо в ней мнемоники не меняются.
Сергей, добрый день.
А сточки зрения стабильности работы программы и парсинга, как лучше делать при ежеминутном цикличном парсинге (программа бесконечно смотрит на сайт и ждет когда там появятся новые ссылки):
1) При каждом цикле парсинга запускать программу планировщиком, программа постоянно перезапускается!
Или
2) Программа постоянно запущена но ссылки постоянно добавляются в конец списка парсинга.
Здравствуйте.
Пояснения на скриншоте.
С уважением к вам, Сергей.
Спасибо, тогда буду использовать этот способ.
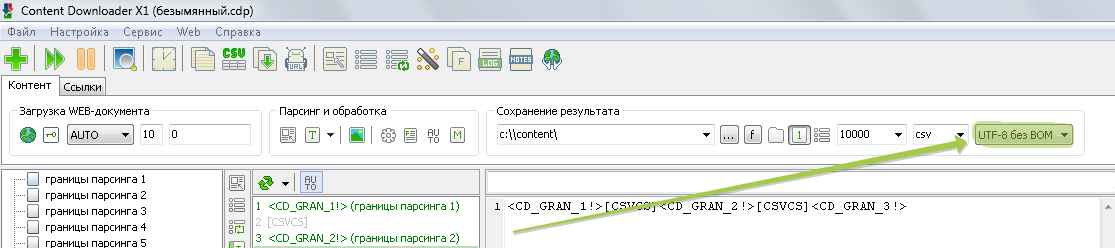
Приветствую! Делаю парсинг в txt файл. Как можно вывести текст “” (без кавычек) – именно текст, а не границу парсинга? т.е. сделать экранирование границы парсинга чтобы она не обрабатывалась.
<CD_GRAN_20!>вот это в кавычках должно было стоять. В первом сообщении текст порезалоЗдравствуйте.
Вот так:
[REPLACE(}|>)]<CD_GRAN_20!}[/REPLACE]С уважением к вам, Сергей.
Сергей, а как то csv файлы можно распарсить при помощи CD ?, есть куча файлов, их бы мне разпарсить .
Сам спросил, сам и отвечу: можно добавить файлы с диска и распарсить их.
Еще вопрос: можно ли каждый цикл повторяющейся границы сохранять в отдельный файл?
Например, я хочу распарсить выдачу яндекса. Через повторяющуюся границу собираю заголовки с 1 по 10 место, а затем через
<CD_CYCLE_GRAN_1!>[DOCNAME][CLEAR][TRANSLITE][INT_ID2].txt[/DOCNAME]
вывожу результат в файл. Вот, нужно это же, только чтобы каждый цикл повторяющейся границы был сохранен в отдельный файл. Тогда в примере получили бы не 1, а 10 файлов.
Пробовал вставить DOCNAME в окне настроек повторяющихся границ (где указано [VALUE]), но там похоже этот макрос не срабатывает
Обратите внимание на этот материал системы помощи http://sbfactory.ru/cd/?p=1984
Спасибо, получилось
А есть ли возможность из гугловской выдачи по типу файла (filetype:abc)скачать эти самые файлы (abc)?
Если да, то как это реализовать?
Сергей, добрый день.
Не подскажете, как то возможно текущим функционалом программы, сделать это?
Сайты отдают по GET запросу CSV файл.
Например:
GET /data/csv?key=9d32tgvfdg324gdfhbaad HTTP/1.1
Ну соответственно и по сылке отдает тоже:
supersite .ru /data/csv?key=9d32tgvfdg324gdfhbaad
CD соответственно этот файл хочет скачать на диск по этой ссылке, но я хочу его распарсить “налету”
Как то можно загнать данные сразу в задание границ парсинга, назначить границы, и вывести через шаблон?
Может как то можно преобразовать расширение на лету на html или txt , или как то еще ?
Вопрос 3: Собираю данные с каталога компаний. На странице компании есть поле для url ее сайта, которое забираю через обычную границу парсинга, например CD_GRAN_3!
Далее собираю емаил адреса с главной страницы сайта, указанного в CD_GRAN_3!, через такую конструкцию:
[EXTRACTEMAILS]<GETMORECONTENT><URL="<CD_GRAN_3!>"><START=""><STARTCOUNT="0"><END=""><ENDCOUNT="0"><PARAMS=""></GETMORECONTENT>[/EXTRACTEMAILS]Еще необходимо собрать емаил со страницы сайта, указанного в CD_GRAN_3!, с раздела “контакты”. Нашел в CD макрос GETURLSBYANCHORS, но вот не могу сопоставить порядок с GETMORECONTENT т.е. мне нужно через GETURLSBYANCHORS найти ссылку на страницу контактов, а потом исползуя уже ее через GETMORECONTENT собрать емаил.
Пробовал такое:
[GETURLSBYANCHORS(конт[NODUP])]<GETMORECONTENT><URL="<CD_GRAN_3!>"><START=""><STARTCOUNT="0"><END=""><ENDCOUNT="0"><PARAMS=""></GETMORECONTENT>[/GETURLSBYANCHORS], но он даже не хочет отрабатывать макрос GETMORECONTENT.Если есть идеи, то прошу помочь. Спасибо.
Не знаю правильная логика или нет, но получилось сделать через задание в переменную var вывода макроса GETMORECONTENT, а дальше GETURLSBYANCHORS с и снова GETMORECONTENT
Подскажите в чем может быть проблема
не собирает ссылки с сайта
sofino ua/double-size-wooden-beds
делаю через WBApp паузы ставлю
60 ссылок и все в тесте клики происходят но результата нет
Здравствуйте.
Нужно настроить автоклик по кнопке “показать все товары”.
Пояснения на скриншоте.
спасибо решено